

What is LAION-5B and why is this work needed?
Recently, multimodal models have shown unprecedented breakthroughs in vision and language tasks. For example, OpenAI’s CLIP model improved the top-1 accuracy by 11.5% in zero-shot image classification on ImageNet. However, this capability is not accessible for all — CLIP was trained on 400M proprietary image-text pairs that are not publicly available. It means researchers outside of OpenAI won’t be able to reproduce CLIP’s performance or improve it.
Before LAION-5B, the largest public dataset with English image-text pairs has 100M examples. LAION-5B dataset brings this number up 20x and provide ~6B English as well as non-English image-text examples. It further push the scale of open datasets for researchers for training and studying state-of-the-art language and vision models. Early experiment results already show that this scale gives strong boost to the performance of few-shot learning and robustness.

Random examples from LAION-5B
What is covered by the paper?
The paper covers three main topics:
Data generation pipeline
The main dataset and the sub-datasets
The research and application work that built on top of the dataset
Data Generation Pipeline
Start from Common Crawl: focus on images with an alt-text
Alt-text is an HTML attribute of IMG tags containing alternative text for description.
Download images from parsed URLs
Cleaning
Remove images of small size or small alt-text
Compute cosine similarities between the image and text encoding and remove pairs with < 0.28 cosine similarity.
Classifying
Perform language detection to classify alt-text into English, another language, or no detected language.
Tag images with inappropriate content

A flowchart of the data acquisition pipeline from LAION-5B’s website.
The main datasets and subdatasets
The main LAION-5B contains three subsets:
2.3 B images with texts in English
2.3 B images with texts in other languages
1.3 B images with language undetected.
I did some search in LAION-5B with common objects (“cat”) to less common ones (“screw”, “suitcase”, and “Andrew Ng”). Categories like “cat” show a big variety of contents, from real cat photos to hand-drawing ones, with a diversity of details and styles. Categories like “screw” and “suitcase” seem to be parsed from shopping websites.

Search in LAION-5B with query “cat”

Search in LAION-5B with query “screw”

Search in LAION-5B with query “briefcase”

Search in LAION-5B with query “Andrew Ng”. Lots of images are profile pictures of his courses.
Subdatasets
LAION-5B is a massive dataset, so it is technically challenging to iterate on. From this large pool of image-text pairs, the research team also curated a few sub-datasets for specific purposes:
LAION-400M: used to reproduce CLIP, relatively easy for trying and experimentation.
LAION-High-Resolution: 170M images to train superresolution models.
LAION-Aesthetic: 120M images considered to be aesthetic.

Examples from the LAION-Aesthetic dataset
Research built on LAION datasets
CLIP Reproduction
The motivation for LAION is to build a massive public dataset that can enable research like CLIP. Therefore, the research team trained OpenCLIP with LAION-400M to validate the data collection pipeline they have built.
One thing to note is that the experiment took up to 400 NVIDIA A100 GPUs to train these models.
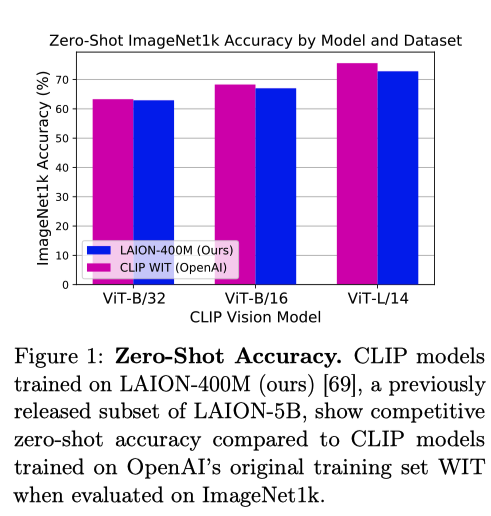
Zero-Shot accuracy of OpenCLIP model trained on LAION-400M vs. the OpenAI’s GLIP models.
Zero-Shot Classification
One thing that really interests me is the capability of zero-shot classification. It illustrates how well a model pretrained on LAION dataset can be used for transfer learning.
Specifically, for each downstream dataset:
Each image will be passed through the image encoder to get their image embedding.
Each class is represented with a set of pre-defined prompts. Its text embedding is defined as the average value over the embedding on the prompts.
The image will be classified as the class whose embedding has the largest cosine similarity with the image embedding.

Few-shot performance of models pertained on LAION subsets on different benchmarks.
In addition to these, LAION-5B has been used to train the latest stable diffusion models for image inpainting and image synthesis.
Thoughts
I am excited about the open release of LAION-5B and a series of its subsets. This is one step towards democratizing the ability to train large-scale vision and language models. Researchers now have access to this open dataset to train multi-modal models and transfer them to a variety of downstream tasks. We have already seen vision and language models being used for generating synthetic chest X-rays, content moderation, image search, robotic manipulation, and etc. Look forward to seeing a proliferation of foundational research as well as industrial applications coming from this open dataset.

Generated from DALL-E with prompt: “An astronaut lounging in a tropical resort in space, futuristic“