
Question Answering (QA) models are often used to automate the response to human questions by leveraging a knowledge base (called “context”). They are commonly seen in practical applications, such as chatbots, customer service centers, or AI assistants. There are a wide variety of question types, including why, what, how, fact-based, and semantic-based, and across a lot of domains, covering news, movies, science, business, etc. Here are two examples:

An example of QA with a long literature paragraph as context.

An example of QA task with a history paragraph as context.
About this Work
Given the variation of QA tasks, robustness is critical for building a generalizable NLP system for such applications. My team at Stanford aims to build a robust question answering system that works across datasets from multiple domains. We explore two architectures, Mixture-of-Experts and Switch Transformer, on their capabilities to extrapolate to out-of-distribution examples at inference. We conduct and analyze extensive experiments to understand the effectiveness of our methods and reach the best combination of our models and techniques through our ablation study.
In this blog post, I am going to share a brief introduction to our work and a summary of our results. For more details, our full paper “Build a Robust QA System with Transformer-based Mixture of Experts“ can be found on arXiv here. We also release our codebase on GitHub here.

Datasets

Statistics for datasets used for building our QA system.
We use three in-domain QA datasets, Stanford’s SQuAD, Microsoft’s NewsQA, and Google’s Natural Questions, for training our QA system, which is evaluated on held-out test examples from three different out-of-domain datasets, DuoRC, RACE, and RelationExtraction. During training, the models see 50,000 training examples from each in-domain dataset and only 127 examples from each out-of-domain dataset for fine-tuning. In the end, we will report performance on the test sets from three out-of-domain datasets. This is a very challenging task and requires our QA system to generalize well beyond the training set.
Approach
While a single network may overfit to the superficial distribution in the in-domain training data, with a meaningful number of expert sub-networks, a gating network that selects a sparse combination of experts for each input example, and careful balance on the importance of expert sub-networks, a sparsely-activated model can train a robust learner that is generalized to out-of-domain datasets. We explore two types of sparsely-activated model architectures:
First, the Sparsely-Gated Mixture-of-Experts: after the output layer of the backbone model, we adds n single fully-connected layer in parallel as experts and another linear layer that serves as the gating function;

The Sparsely-Gated Mixture-of-Experts architecture from Google Brain (the original paper can be found here)
Secondly, the Switch Transformer: we bring the MoE layers up to the middle of the backbone and replace the dense feed forward network with a sparsely-activated switch FFN layers.
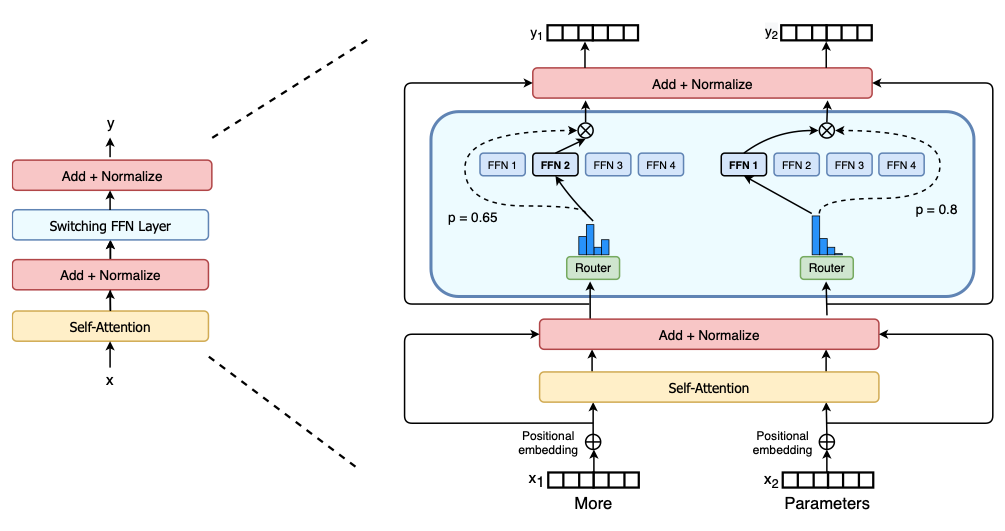
The Switch transformer architecture (the original paper can be found here)
In addition to novel architectures, data augmentation can also boost performance and robustness of training. We explored two techniques:
Easy data augmentation (EDA) techniques, including synonym replacement, random deletion, random swap, and random insertion, have shown effectiveness on small datasets, despite their simplicity.
Back translation is another technique that has also been shown to improve reading comprehension performance, thus gaining popularity. In this project, we use Spanish, French, and German as intermediate languages.
Summary of Results
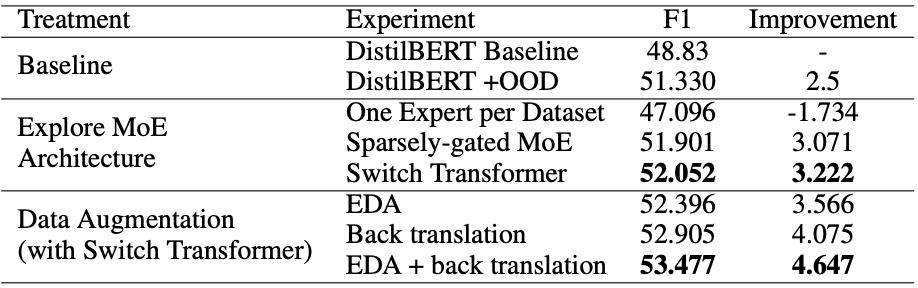
An ablation study of model architectures and data augmentation. The performance reported is the F1 achieved on the out-of-domain validation dataset. The column ‘Improvement’ indicates the improvement over baseline).
First, with the baseline DistilBERT model, we improve the F1 by simply including the Out-of-Domain examples in the training set.
In the comparison between the MoE architecture, we find both Sparsely-gated MoE and the Switch Transformer achieve better performance over the DistilBERT baseline. The Switch Transformer pushes the performance by 3.222 to 52.052!
Then, we evaluate the effectiveness of data augmentation techniques with the Switch Transformers. We observe an improvement of 0.344 and 0.853 respectively with Easy Data Augmentation (EDA) and Back translation. When they are applied together with the Switch Transformer, we see an even higher F1 score of 53.477. This means different data augmentation techniques can complement each other. In future work, we recommend exploring other different data augmentation techniques to see if the performance can be lifted to a higher level.
The combination of our best MoE architecture and data augmentation achieves a 53.477 F1 score in the out-of-domain validation set, which is a 9.52% performance gain over the baseline. On the final test set, we reported a higher 59.322 F1 and 41.995 EM. This effectively shows the robustness of our QA system.
In the “Experiments” section of our paper here, we shared a detailed analysis of the quantitative effectiveness of the number of experts, data augmentation methods, and the load balancing loss of our models.
We also did a qualitative evaluation by reviewing our model’s prediction of the out-of-domain examples and comparing them with the corresponding groundtruth answers. Here are several examples below. Overall, we find our system provides reliable and reasonable answers to most of the context-questions pairs!




Conclusion
Our combination of the best model architecture and data augmentation achieves a 53.5 F1 score, which is a 9.5% performance gain over the baseline. On the final test set, we reported a higher 59.5 F1 and 41.6 Exact Match (EM). We successfully demonstrate the effectiveness of Mixture-of-Expert architecture in a Robust QA task. Based on the qualitative analysis, we find our model is very reliable and accurate at answering fact-based questions whose answers can be found from the context paragraph; it occasionally fails at questions that require complex reasoning or summarizing the long paragraphs. This points to future improvements.
This work is done together with my amazing colleague Yuanzhe Dong and Xixuan Liu. Our full paper “Build a Robust QA System with Transformer-based Mixture of Experts“ can be found on arXiv here. We also release our codebase on GitHub here.
If you have any question, please feel free to reach me via the link below: