
The OpenAI team built a new benchmark dataset called SimpleQA that evaluates large language models' (LLMs) ability to answer factual questions. A particularly intriguing aspect of this paper is, in this era of LLMs, how the team of researchers leverages LLMs in their own workflow to design, iterate, and analyze a new dataset.

The SimpleQA dataset contains 4,326 short, fact-seeking questions. The questions are designed to be high quality — grounded in facts, easy to grade, covering a wide range of topics, timeless, and challenging for frontier models.
Here is the link to the paper and the link to the GitHub repository.
Building the Dataset with Human + AI
The data collection and verification process in the section 2 is the most important part in the paper. It explains how the team ensures the high quality of the datasets, specifically:
In the question creation stage:
Humans wrote all the questions, and then GPTs analyzed them to detect any violations of design criteria, such as multiple possible answers or missing units. Questions that were flagged were sent back to humans for revision.
GPTs then rewrote the questions to improve their writing quality.
In the verification stage:
A second human answered each question without seeing the answer. A ChatGPT-based classifier judged whether the two human-provided answers agreed with each other. Questions with disagreeing answers were removed.
Humans reviewed each question to check for any violation of the design criteria. Questions flagged with violation were removed.
Note that this step seems redundant with the first step in the creation stage, where a GPT had one pass through the dataset to detect violations. Not clear what motivated the team to re-do this step to further filter questions.
Both human annotators provided references for their answers. Only questions with two unique website domains among references were kept.
Grading Human Performance with AI
The research team also use ChatGPT to grade and establish human performance on the dataset:
A third group of human was given 1000 sampled questions to answer
The answers were evaluated using a ChatGPT grader. The answers achieved 94.4% accuracy.
The team went through each of the 56 answers that were classified as incorrect, among which:
15 were false negatives by the grader
7 were due to incomplete answers by the human respondents
6 had correct source but contracting answers.
28 were actual incorrect answers, attributed to factors such as ambiguous questions or questions with multiple correct answers.
Based on this analysis, the team concluded that the human-level performance on the dataset was around 97% (100% - 3% actual incorrect answers).
Tag the Dataset with AI
The research team used ChatGPT to extract more quantitative insights from the SimpleQA dataset, including:
Tagging questions with topics (e.g., Science & Technology, Politics, Art)
Classifying answers by types (e.g., dates, person names, numbers, places)
Analyzing the distribution of sources by domains
This AI-assisted tagging and analysis process helps understand the composition and characteristics of the dataset:
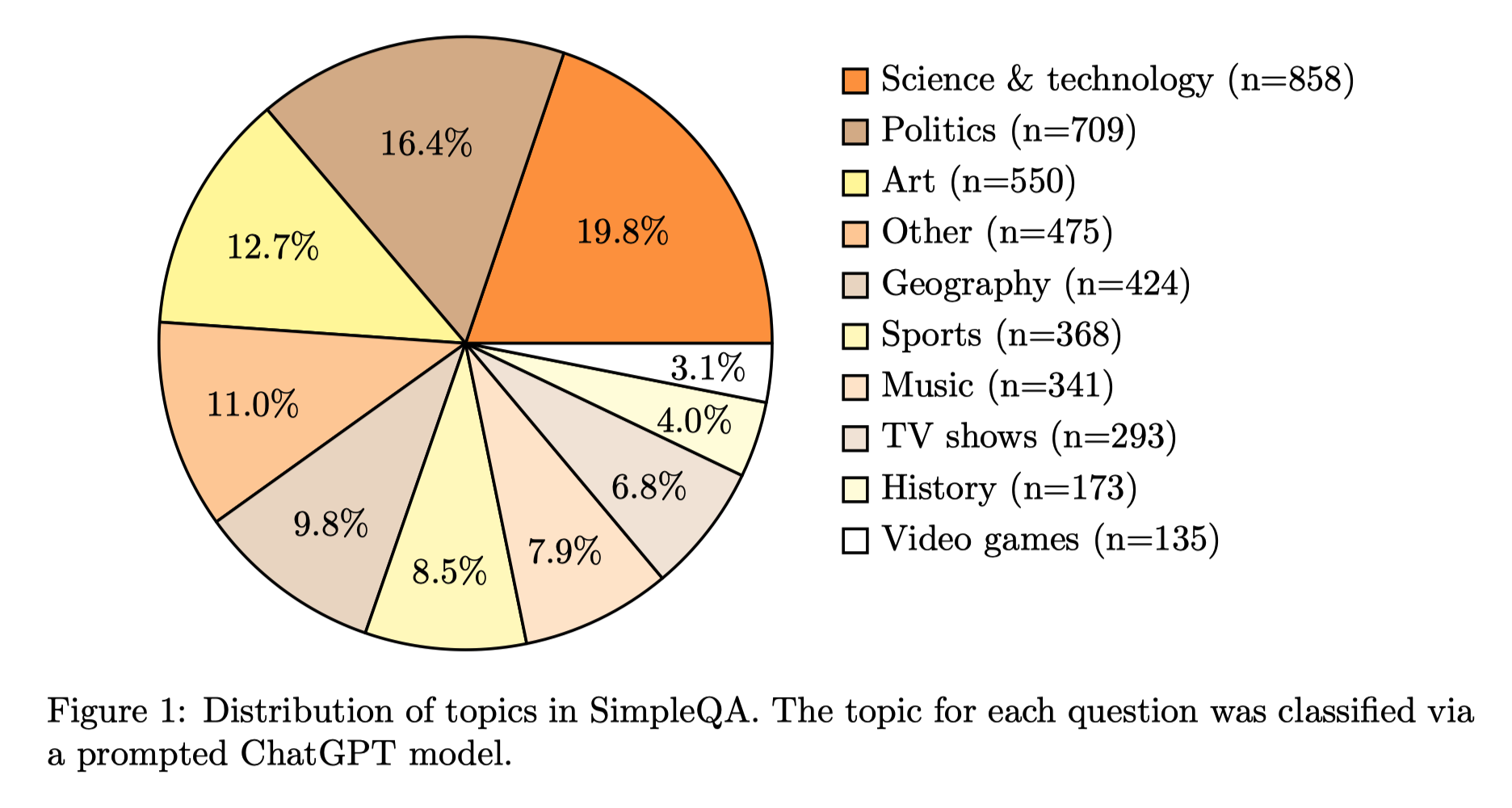
Grading Model Responses with AI
In model evaluation process, a ChatGPT classifier grades the responses from all models against the reference answer. Here is the prompt for the grader/judger model.
To provide more granular insights, the researchers further categorized the incorrect answers into two subgroups: incorrect and not attempted. This breakdown helps distinguish between cases where the model provided an incorrect response and instances where it did not attempt to answer the question at all.
To advocate for a single-number metric, the team computed an F-score based on the overall correct answer (like recall) and the correct answers given attempted questions (like precision).
Briefly on the results:
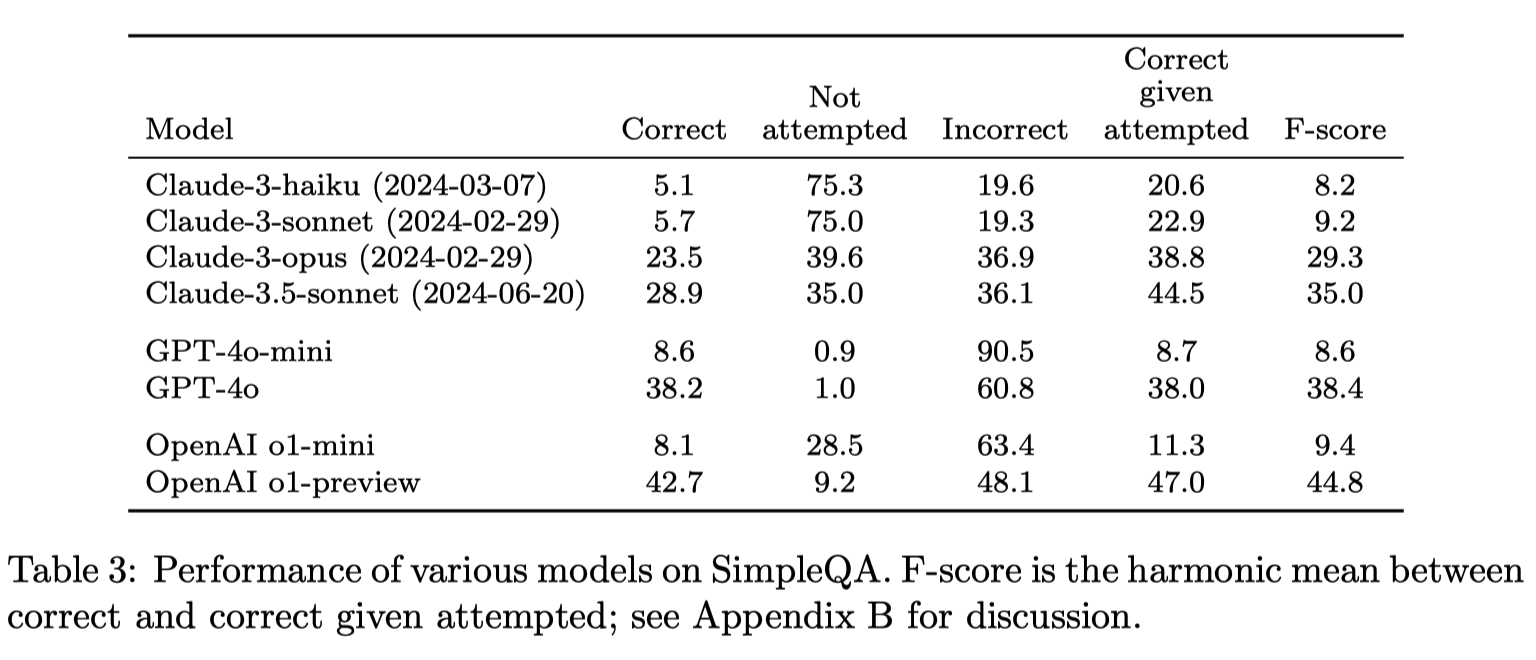
Larger models tend to achieved more correct answers and attempt more.
4o models, the big one as well as the mini one, tend to attempt on most of the questions; as a result, they scored high on correct and also incorrect.
Claude tends to “not attempt” on many questions, reflecting its ability to say “I don’t know”.
Thoughts
One interesting aspect of recent papers from leading AI labs is learning how they integrate large language models (LLMs) into their workflows, including data cleaning, categorization, and evaluation. For example, in the Llama 3 paper, Meta's team shared that they use earlier developed Llama models to rewrite data during pretraining and post-training. Similarly, in this paper, the OpenAI team demonstrated how they leverage LLMs in their process of building a new benchmarking dataset for AI models, improving data quality, gaining insights, and automating the evaluation of free-form responses.
In the past, when working on building proprietary datasets, tremendous effort was spent on tuning the process and relying on human experts' knowledge to iterate on data quality. However, with the advent of sufficiently intelligent and low-cost AI models, a new way to iterate data quality at scale has emerged. This involves running consensus among many expert models to surface inconsistencies, tagging each example in a large dataset instantaneously, and obtaining feedback on model predictions. These AI models help automate mundane tasks, while simultaneously making human expertise more valuable and impactful. Humans can now focus on providing expert knowledge to create labeling rules, make judgments on misalignments, and design workflows for building datasets for specific purposes.
It is fascinating to explore how we can further push in this direction to better combine the strengths of AI and human expertise. By leveraging the capabilities of LLMs and human knowledge, we can create high-quality datasets more efficiently and effectively, and ultimately advance the AI applications in various domains.