
The is my reading note on the research paper Thinking LLMs: General Instruction Following with Thought Generation from Meta.

Goal: Improve LLMs’ response quality by training them to think before answering.
Major Takeaways:
Existing post-training datasets and reward models lack information on thought processes, posing a barrier to providing LLMs with supervision to learn the thinking process.
Thought Preference Optimization (TPO): iteratively train the model to generate a thought process followed by the response. In each iteration, present the response without thought to the judge to select the best thought.
TPO initially underperforms the direct prompt baseline but shows better performance after a few iterations.
TPO demonstrates significant performance gains on non-reasoning categories, including translation, marketing, and health; reasoning categories like math and analysis also show improvements.
Some judge models tend to favor longer responses, resulting in the LLM learning to output longer responses through thought iteration. This issue can be effectively mitigated by penalizing longer responses.
Thought Preference Optimization (TPO)
Iteratively Improve Thought Process
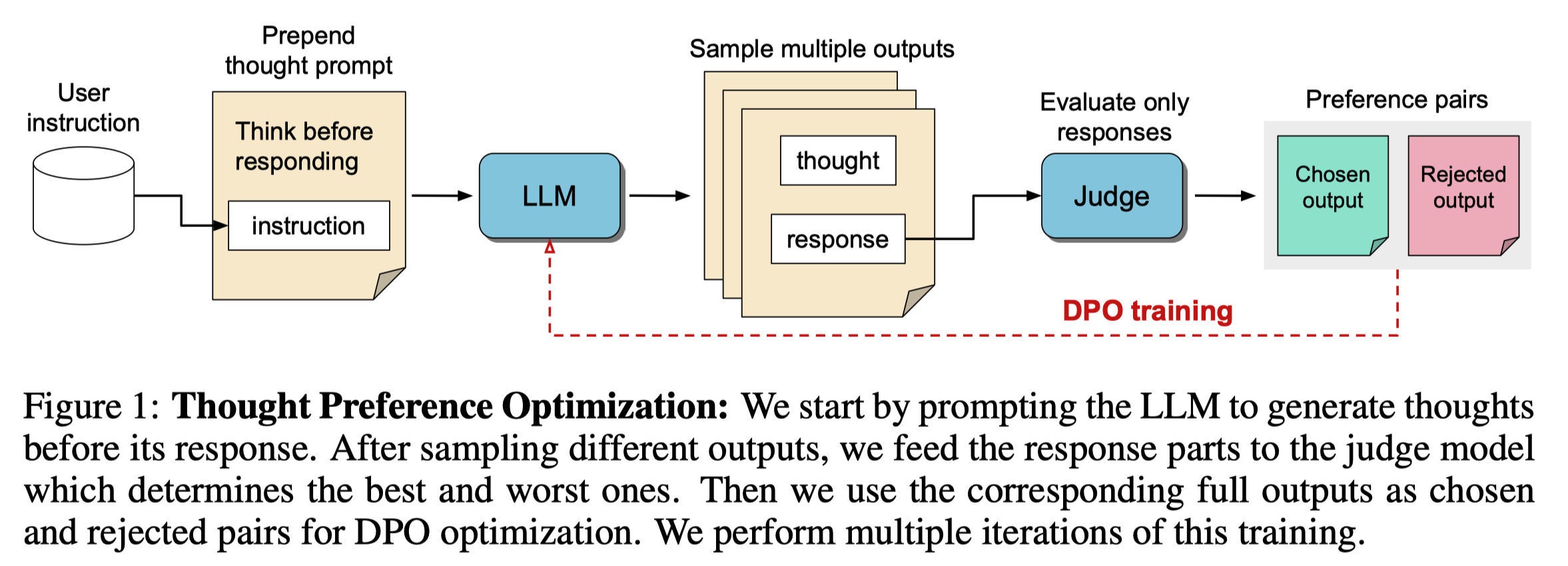
Start with an instruction-tuned LLM
For a set of instructions:
For a given instruction, prompt the model to generate its thought process and then the response (thought prompting)
Use a judge model to evaluate (only) the responses and build preference pairs.
Train the model using Direct Preference Optimization (DPO) to improve the quality of the thought process and response, based on the quality of the response.
Repeatedly improve the LLM, using new instruction sets in each epoch.

From experiments, one important observation is that the Thought Prompting model actually underperforms the baseline. The authors believe that the seed model has been well optimized for directly generating a response (with or without Chain of Thoughts), so modifying its response style hurts the performance. However, the validity of this explanation remains uncertain.
One thing is certain: Thought Prompting does not provide immediate benefits when applied to existing models; it requires a few iterations of Thought Preference Optimization (TPO) to improve performance in the post-training stage.

With TPO, Llama-3-8B was able to achieve an impressive result in AlpacaEval.

The paper breaks down the evaluation dataset into 20 categories. TPO demonstrates significant performance gains on non-reasoning categories, including translation, marketing, and health; reasoning categories like math and analysis also show improvements.
Hidden Thought
A critical decision in the Thought Prompting approach is to keep the thought process hidden.
The thoughts are hidden from the users for two main reasons:
For general questions, users expect to receive a response without excessive intermediate reasoning steps.
Hiding the thought process offers more flexibility for techniques to improve thought, such as making and revising mistakes and conducting self-evaluation.
The thoughts are also hidden from the judge due to:
The lack of a judge model capable of evaluating internal thoughts. However, this constraint could be lifted with the progress of Process-Supervised Reward Models (PRMs).
The alignment with the final objective of providing high-quality responses to the user.
Different Prompt Templates
Generic Thought Prompt: thought followed by response
Respond to the following user query in a comprehensive and detailed way. You can write down your thought process before responding. Write your thoughts after “Here is my thought process:” and write your response after “Here is my response:”.User query: {user instruction}Specific Thought Prompt: thought followed by self-evaluation, finally response
Respond to the following user query in a comprehensive and detailed way. But first write down your internal thoughts. This must include your draft response and its evaluation. After this, write your final response after “<R>”.User query: {user instruction}According to the experiments, there is not much difference between these two templates in terms of win rate. However, the Specific Thought Prompt with self-evaluation leads to longer responses and achieves a higher average score with the ArmoRM judge.
Judge Models
The judge model evaluates all responses and compute ELO score
For each input prompt, a model generates K=8 outputs.
Two judge models:
Self-Taught Evaluator (STE): based on Llama-3-70B-Instruct; it outputs preference between two responses in natural lanaguage.
ArmoRM: 8B reward model that directly outputs a scalar score to a single response.
On both benchmarks, better results are achieved with ArmoRM judge.
Build Preference Datasets
Instruction Datasets:
Assume that there is no provided human-generated thought data for fine-tuning.
Start with a set of synthetic instructions generated from Llama-2-70B-Chat with few-shot prompting.
In later iterations, switched to UltraFeedback and use 5k instructions that were unseen by the model before.
Length Control
This is a useful takeaway from the paper: some judge models tend to favor longer responses; as a result, through training iterations, this bias could be learned from the LLM and the response becomes longer very rapidly. This issue can be mitigated by penalizing longer responses:

Where l is the length of a response, and ho is a hyper-parameter to control the strength of length-control penalty. From experiments, ho in [0, 0.5].
This turned out to be very effective and become a must — the model did not growth their response length much during training.
Other Takeaways from Experiments
Despite of better results on two benchmarks (AlpacaEval and Arena-Hard), TPO models achieved worse result than the baseline model on the GSM8K dataset (Math domain). The authors suspect it is due to 1) the base model is already optimized for Math with CoT, and 2) lack of math-related instructions in the overall dataset (2.2%). Incorporating more math instructions during training and having access to a judge capable of evaluating of their answers are likely solutions.
Without direct supervision, the model learns to shorten and condense the thought throughout the training.
To defend parsing errors (of thoughts and final answers): in the preference data creation process, add responses with parse errors as rejected examples (no more than 10%).